Amazon AuroraでのSlaveのインスタンスサイズについて議論したのでそのメモ
はじめに
現在、構築中の本番環境では検証の末 Amazon Aurora を使用することになりそうです
それにあたってSlaveをどうするか少し議論(?)になったので自分用のメモの意味も込めて残してきます
以前の環境
この話をするために今までの環境を確認したいと思います
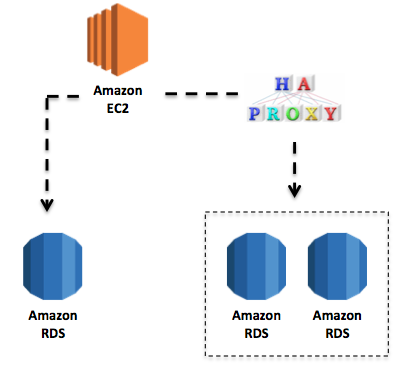
今までの環境は Amazon RDS で下記の様な構成を取っていました
- master x 1
- slave x 2
- 管理画面用slave x 1
slaveへは各Webサーバーで起動しているhaproxyでバランシングしています。
スペックですが slave用のRDSは master用のRDSに比べてスペックを低くしてあります。
雑に図にするとこんな感じです
検討した構成
Auroraはフェイルオーバーの際にReplicaのどれかがマスターに昇格します。
そのため以前と同様に、slaveをmasterよりも低いスペックで運用してしまうとmasterがフェイルオーバーした際にスペックの低いDBがmasterに昇格しDBの負荷が高くなるという二次障害が起きてしまう可能性があります。
どのような構成にしようか以下のパターンが出ました
パターン1
今まで通り
master x 1
masterよりも低いスペックのslave x 2
masterと同じスペックのslave x 1 をstand by状態にしておく
これだとmasterがフェイルオーバーしてもと同等のspecのサーバーに切り替わるのでスペック的なところで問題ない
ただ、 同様のスペックをstand byにしておくので勿体無い
ということで次のパターンを考えました
パターン2
master x 1
masterと同等のスペックのslave x 2
これだとmasterがフェイルオーバーしてslaveがmasterに昇格してもスペック的なところでは問題ない
しかし、 slaveがマスターに昇格してもhaproxyからslaveとして参照され続けるので master + slave 両方のアクセスが有り負荷が高まる恐れがある
構築中の環境
構成は、以上のことをふまえてパターン2 にすることにしました。
- master x 1
- slave x 2
以前の環境と代わりませんがslaveのスペックが大きくしました。
で、パターン2ででていた問題ですが、
haproxy 1.6 から入った external-check を使用してmasterに昇格したらslave参照をしない
という設定をhaproxy側で行う予定です。 こちらは現在検証中です。